

Unlock performance: Accelerate Pandas operation using Polars
Image of the author | Idiom
introduce
polarity Currently one of the fastest open source libraries for data manipulation and processing on a single computer, with an intuitive and user-friendly API. It is fixed in rust and is designed to optimize low memory consumption and speed when using data frames.
This article visits Python’s Polars library and explains how to use it seamlessly similar to Pandas to effectively manipulate large datasets.
Settings and data loading
Throughout the entire useful code example shown, we will use the well-known version California Housing Dataset Provided in this repository. This is a medium-sized dataset containing a combination of numerical and categorical attributes that describe the housing and demographic characteristics of each district in California.
If you use the Polars library for the first time, you may need to install the Porars library:
Remember to add “!” at the beginning of the above command if you work on some laptop environment.
Now it’s time to import the Polars library and use it to read the dataset:
|
import polarity As pl URL = “ https://raw.githubusercontent.com/gakudo-ai/open-datasets/refs/refs/heads/main/housing.csv” DF = pl.read_csv((URL) |
As you can see, the process of loading a dataset is very similar to Pandas and has the same name function read_csv().
Viewing the first few lines is also similar to the panda equivalent method:
But unlike giant pandas, Polars provides a dataframe property to view the dataset pattern, i.e. a list of attribute names and their types:
Output:
Schema([('longitude', Float64), ('latitude', Float64), ('housing_median_age', Float64), ('total_rooms', Float64), ('total_bedrooms', Float64), ('population', Float64), ('households', Float64), ('median_income', Float64), ('median_house_value', Float64), ('ocean_proximity', String)])
Check the output to understand the dataset we will use.
Accelerate data operation
Now that we are familiar with the loaded datasets, let’s see how we can use Porars to apply various operations and operations to our data in an efficient way.
The following code applies a missing value archive strategy to fill in some non-existent values total_bedrooms Attribute, use the median attribute:
|
median_bedrooms = DF.choose((pl.Colonel((“total_bedrooms”).Median(()).thing(() DF = DF.with _columns(( pl.Colonel((“total_bedrooms”).fill_null((median_bedrooms) ) |
this with_columns() Call the method to modify the specified column, i.e. fill in the missing values with the previously calculated median property.
How to continue to carry out certain functional engineering, pole? Let’s create some new features based on existing interactions to the room ratio of each family room, each room bedroom and population.
|
DF = DF.with _columns(([ (pl.col(“total_rooms”) / pl.col(“households”)).alias(“rooms_per_household”), (pl.col(“total_bedrooms”) / pl.col(“total_rooms”)).alias(“bedrooms_per_room”), (pl.col(“population”) / pl.col(“households”)).alias(“population_per_household”) ]) |
An important note at this point is: So far, we are using Polars’ eager execution mode, but the library has two modes: desire and laziness.
exist An urgent patterndata operations are carried out immediately. at the same time, Lazy execution mode By using certain features (e.g. collect(). Polars Lazy mode, activated by using lazy()Optimize the order of follow-up operations on this data frame before applying any calculations. This approach can make the execution of complex data processing workflows more efficient.
If we take a few steps back and we want to do the same thing to blame for the missing values and feature engineering patterns, we will do the following:
|
LDF = DF.Lazy(() LDF = LDF.with _columns(( pl.Colonel((“total_bedrooms”).fill_null((pl.Colonel((“total_bedrooms”).Median(()) ) LDF = LDF.with _columns(([ (pl.col(“total_rooms”) / pl.col(“households”)).alias(“rooms_per_household”), (pl.col(“total_bedrooms”) / pl.col(“total_rooms”)).alias(“bedrooms_per_room”), (pl.col(“population”) / pl.col(“households”)).alias(“population_per_household”) ]) # Once we use collect(), the calculation will actually be applied result_df = LDF.collect(() exhibit((result_df.head(()) |
When executed, you should feel fast, light and breeze.
Let’s end up with an example showing more data operations in lazy mode (although this article is not explicitly used, you may need to place something like result_df = ldf.collect() and display(result_df.head()) No matter where you want to calculate.
Filter area Locations where median home value is above $5:
|
ldf_filtered = LDF.filter((pl.Colonel((“median_house_value”) > 500000) |
Grouping area The ocean is close to the “type” (a classified property) and obtains the average house value for each area:
|
avg_house_value = LDF.group_by((“Ocean_Proximity”).agg(( pl.Colonel((“median_house_value”).Meaning(().Alias((“avg_house_value”) ) |
A word of caution: Functions grouped by categories in Polars are called group_by() (no groupby()please note that underscores are used).
If we just try to access avg_house_value Without really performing the action, we get a visual of the stage pipeline:
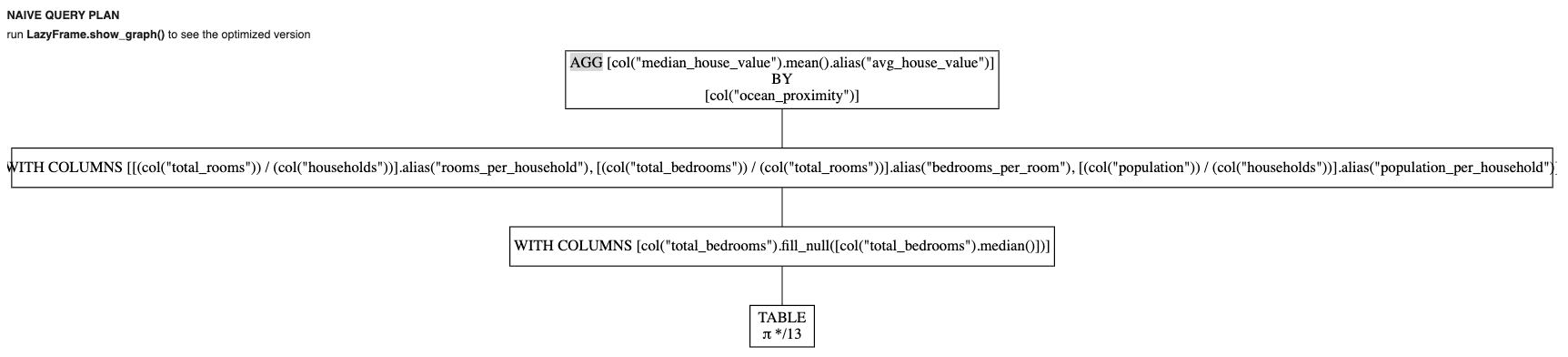
So we have to do something similar:
|
avg_house_value_result = avg_house_value.collect(() exhibit((avg_house_value_result) |
Summarize
Polars is a lightweight and effective alternative to manage complex data preprocessing and cleaning workflows within the data range like Pandas. This article shows how to use this library in Python to desire and lazy execution patterns, thus customizing how to plan and execute data processing pipelines.