

Custom fine-tuning for domain-specific LLM.
Image of the author | Idiom
Introduction to Custom LLM Fine Tuning
Fine-tuning a Big language model (LLM) is a process that takes a pre-trained model – usually a huge model of GPT or Llama models with millions to billions of weights – and continue training it, exposing it to new data in order to update the model weights (or usually part of it). This can be done for a number of reasons, such as keeping the LLM up to date with the latest data, or tweaking it to specialize in narrower, more domain-specific tasks or applications.
This article discusses and illustrates the latter reason for fine-tuning LLM, unveiling custom LLM fine-tuning to make your model domain model specific.
It is important to clarify that with “custom fine-tuning”, we will not refer to specific or different methods of fine-tuning the LLM. Generally speaking, the micro-tuning process is almost the same regardless of whether the purpose is to adjust it to a specific domain: the key difference is the data used for training, which in the case of custom fine-tuning, is specially curated so that its scope specifically spans the target domain, style, style, or application. Using custom fine-tuning for specific domain datasets can help your model better understand professional terms and domain-related requirements and nuances.
The following figure illustrates the nature of custom LLM fine-tuning for domain-specific LLM:
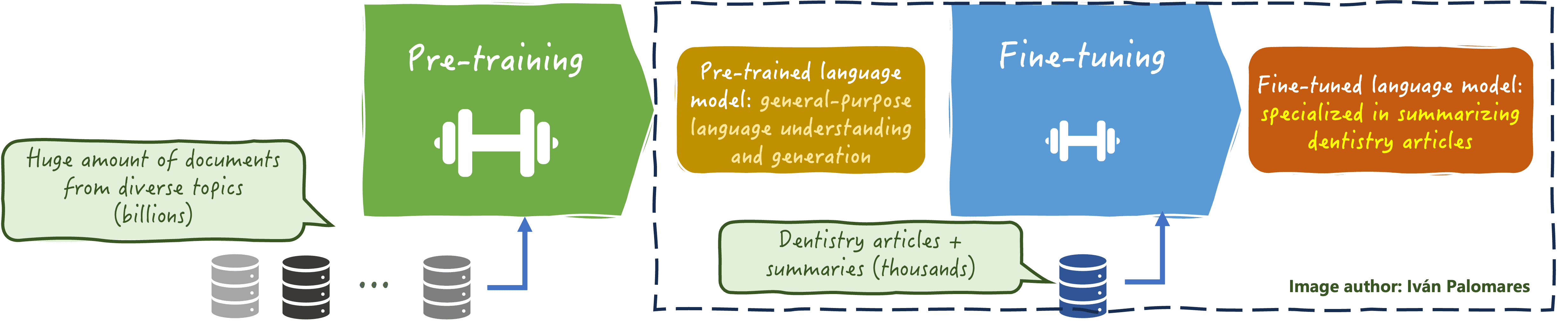
Custom LLM fine tune
Image of the author
Some important elements and aspects of custom LLM fine tuning are:
- this data Used to fine-tune your LLM must have high quality yes Relatedincluding representative language patterns, terms and expressions (terms), which may be unique to your target field, whether it is dentistry, Zen Buddhism principles or cryptocurrencies, can be named some.
- Some domain-specific data needs Deep factual knowledge LLM learns effectively from it. A successful fine-tuning process should be able to extract this in-depth knowledge from the data and inject it into the “model’s DNA” to minimize the risk of generating inaccurate information about the domain once fine-tuning is done.
- Compliance, liability and licensing It is also a key aspect to consider. Custom LLM fine-tuning processes should ensure consistency between models and ethical and industry standards and regulations to mitigate possible risks. Sometimes, models with restricted licenses, such as Apache licenses, help with greater customization and control of your fine-tuning model.
- Continuous monitoring and evaluation After fine-tuning, it is essential to ensure that the domain-specific fine-tuning process is successful and that the renewed LLM is now more efficient in the expected new range.
Explanatory Custom Fine Tuning Example in Python
Let’s take a look at a practical example of customizing a relatively manageable LLM falcon-rw-1b (approximately 1.3 billion parameters) can be obtained through the Transformers library that embraces Face. The goal is not to go through the code in detail, but to outline the main practical steps involved in custom LLM fine-tuning:
1. Set and start
When using embracing facial models, fine-tuning usually requires identifying the type of the LLM and the type of the target task, such as (e.g., text generation), and loading the appropriate Automatic lessons The model used to manage this type (in this example, AutoModelForCausalLM). this Trainer and TrainingArguments It must also be imported as they will play a fundamental role in the fine-tuning model.
And, of course, each loaded pretrained model must be paired with the relevant tokenizer to properly manage data input.
|
pip Install transformer Dataset peft bitsandbytes accelerate |
|
from transformer import AutomodelForCausAllm,,,,, AutoTokenizer,,,,, Trainer,,,,, Training from Dataset import Dataset from peft import Loraconfig,,,,, get_peft_model model_name = “tiiuae/falcon-rw-1b” Token = AutoTokenizer.From _reted((model_name) if Token.pad_token yes Nothing: Token.pad_token = Token.eos_token Model = AutomodelForCausAllm.From _reted((model_name,,,,, load_in_8bit=real,,,,, device_map=“car”) |
2. Acquire and prepare data for specific areas
We are considering a small dataset – in a real fine-tuning process, which will be a larger dataset – including Q&A pairs related to chronic diseases. This is totally OK for the attitude of llm generated in text, just like the llm we load, because one of the tasks it can perform seamlessly is to avoid generative questions (rather than extractive questions, the model attempts to extract answers from existing information for existing information).
|
domain_data = [ {“text”: “Q: What are the symptoms of diabetes? A: Increased thirst, frequent urination, fatigue.”}, {“text”: “Q: How is hypertension treated? A: Through lifestyle changes and medications.”}, {“text”: “Q: What causes anemia? A: Low levels of iron or vitamin B12 in the body.”} ] Dataset = Dataset.From _list((domain_data) defense tokenize_function((example): return Token((example[“text”],,,,, filling=“max_length”,,,,, Cutoff=real) tokenized_dataset = Dataset.map((tokenize_function,,,,, Batch processing=real) |
The dataset is marked before fine-tuning the model.
3. Fine-tuning model
This process involves instantiation TrainingArguments and Training Instance, we set configuration aspects such as the number of training rounds and learning rates, train() Methods and save the fine-tuning model. Optionally, the fine-tuning process is made lighter by important parts of the smart freezing model weighting, such as LORA (low-level adaptation).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 twenty one twenty two twenty three twenty four 25 26 27 28 29 30 31 |
lora_config = Loraconfig(( r=8,,,,, lora_alpha=16,,,,, target_modules=[“query_key_value”],,,,, lora_dropout=0.05,,,,, bias=“Nothing”,,,,, task_type=“CAUSAL_LM” ) Model = get_peft_model((Model,,,,, lora_config) Training_args = Training(( output_dir=“./result”,,,,, per_device_train_batch_size=2,,,,, num_train_epochs=2,,,,, logging_steps=10,,,,, save_steps=20,,,,, save_total_limit=2,,,,, optimal=“paged_adamw_8bit”,,,,, Learning_rate=2e–4,,,,, ) Trainer = Trainer(( Model=Model,,,,, args=Training_args,,,,, train_dataset=tokenized_dataset,,,,, ) Trainer.train(() Model.save_preted((“./custom-finetunedlm”) Token.save_preted((“./custom-finetunedlm”) |
Summarize
In this article, we provide a balanced overview (theoretical and practical) that are processes that customize mini-language models to adapt them to more specific areas. This is a computing-intensive process that requires high-quality representative data to succeed.